‘Off label’ Use of Imaging Databases Could Lead to Bias in AI Algorithms, Study Finds
Significant advances in artificial intelligence (AI) over the past decade have relied upon extensive training of algorithms using massive, open-source databases. But when such datasets are used “off label” and applied in unintended ways, the results are subject to machine learning bias that compromises the integrity of the AI algorithm, according to a new study by researchers at the University of California, Berkeley, and the University of Texas at Austin.
The findings, published today (Monday, March 21) in the Proceedings of the National Academy of Sciences, highlight the problems that arise when data published for one task are used to train algorithms for a different one.
The researchers noticed this issue when they failed to replicate the promising results of a medical imaging study. “After several months of work, we realized that the image data used in the paper had been preprocessed,” said study principal investigator Michael Lustig, UC Berkeley professor of electrical engineering and computer sciences. “We wanted to raise awareness of the problem so researchers can be more careful and publish results that are more realistic.”
The proliferation of free online databases over the years has helped support the development of AI algorithms in medical imaging. For magnetic resonance imaging (MRI), in particular, improvements in algorithms can translate into faster scanning. Obtaining an MR image involves first acquiring raw measurements that code a representation of the image. Image reconstruction algorithms then decode the measurements to produce the images that clinicians use for diagnostics.
Some datasets, such as the well-known ImageNet, include millions of images. Datasets that include medical images can be used to train AI algorithms used to decode the measurements obtained in a scan. Study lead author Efrat Shimron, a postdoctoral researcher in Lustig’s lab, said new and inexperienced AI researchers may be unaware that the files in these medical databases are often preprocessed, not raw.
As many digital photographers know, raw image files contain more data than their compressed counterparts, so training AI algorithms on databases of raw MRI measurements is important. But such databases are scarce, so software developers sometimes download databases with processed MR images, synthesize seemingly raw measurements from them, and then use those to develop their image reconstruction algorithms.
The researchers coined the term “implicit data crimes” to describe biased research results that result when algorithms are developed using this faulty methodology. “It’s an easy mistake to make because data processing pipelines are applied by the data curators before the data is stored online, and these pipelines are not always described. So, it’s not always clear which images are processed, and which are raw,” said Shimron. “That leads to a problematic mix-and-match approach when developing AI algorithms.”
Too good to be true
To demonstrate how this practice can lead to performance bias, Shimron and her colleagues applied three well-known MRI reconstruction algorithms to both raw and processed images based on the fastMRI dataset. When processed data was used, the algorithms produced images that were up to 48% better — visibly clearer and sharper — than the images produced from raw data.
“The problem is, those results were too good to be true,” said Shimron.
Other co-authors on the study are Jonathan Tamir, assistant professor in electrical and computer engineering at the University of Texas at Austin, and Ke Wang, UC Berkeley Ph.D. student in Lustig’s lab. The researchers did further tests to demonstrate the effects of processed image files on image reconstruction algorithms.
Starting with raw files, the researchers processed the images in controlled steps using two common data-processing pipelines that affect many open-access MRI databases: use of commercial scanner software and data storage with JPEG compression. They trained three image reconstruction algorithms using those datasets, and then they measured the accuracy of the reconstructed images versus the extent of data processing.
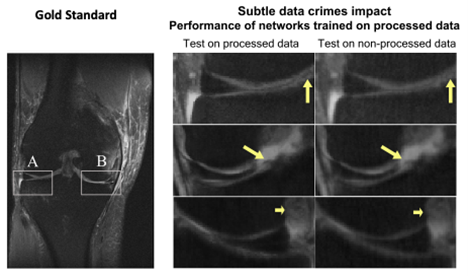
“Our results showed that all the algorithms behave similarly: When implemented to processed data, they generate images that seem to look good, but they appear different from the original, non-processed images,” said Shimron. “The difference is highly correlated with the extent of data processing.”
‘Overly optimistic’ results
The researchers also investigated the potential risk of using pre-trained algorithms in a clinical setup, taking the algorithms that had been pre-trained on processed data and applying them to real-world raw data.
“The results were striking,” said Shimron. “The algorithms that had been adapted to processed data did poorly when they had to handle raw data.”
The images may look excellent, but they are inaccurate, the study authors said. “In some extreme cases, small, clinically important details related to pathology could be completely missing,” said Shimron.
While the algorithms might report crisper images and faster image acquisitions, the results cannot be reproduced with clinical, or raw scanner, data. These “overly optimistic” results reveal the risk of translating biased algorithms into clinical practice, the researchers said.
“No one can predict how these methods will work in clinical practice, and this creates a barrier to clinical adoption,” said Tamir, who earned his Ph.D. in electrical engineering and computer sciences at UC Berkeley and was a former member of Lustig’s lab. “It also makes it difficult to compare various competing methods, because some might be reporting performance on clinical data, while others might be reporting performance on processed data.”
Shimron said that revealing such “data crimes” is important since both industry and academia are rapidly working to develop new AI methods for medical imaging. She said that data curators could help by providing a full description on their website of the techniques used to process the files in their dataset. Additionally, the study offers specific guidelines to help MRI researchers design future studies without introducing these machine learning biases.
Funding from the National Institute of Biomedical Imaging and Bioengineering and the National Science Foundation Institute for Foundations of Machine Learning helped support this research.