California Language Archive clicks with multiple resources
As of today (Monday, June 20), much of the University of California, Berkeley’s vast language resources is accessible, free of charge, to anyone with Internet access via the new California Language Archive (CLA) website and its catalog of UC Berkeley materials – the largest indigenous language archive at a U.S. university.
The site is filled with downloadable digital content that includes rare audio recordings and written documentation. A few examples include 51 hours of Wintu songs and conversations, the hummingbird fire story recited in the nearly extinct language of Nisenan, and handwritten notes on Chochenyo that are based on linguist and ethnographer J.P. Harrington’s work with the language’s last good speaker.
“This very extensive information is valuable for scholars, and absolutely vital for Native American communities trying to revitalize endangered or no longer spoken languages,” said Andrew Garrett, a UC Berkeley professor specializing in historical linguistics and the driving force behind the CLA.
The campus’s extensive sound recordings and written data on indigenous California languages typically have been available to scholars, Native communities and others – only during regular business hours, and scattered among multiple campus locations.
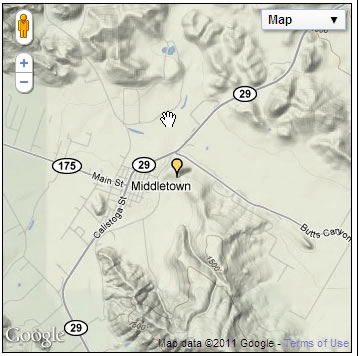
The new, easy access to information, according to Garrett, “will make a huge difference” in the study and preservation of endangered Native American languages, and in researchers’ ability to use the site’s links to actual geographic locations for the sound and document records to map the many layers of California’s language diversity.
The archive has a special focus on California, but includes languages all the way from Alaska to South America and from the Pacific Ocean to the Atlantic. It is the online face of a collaboration/unification of two distinct UC Berkeley archives – the Berkeley Language Center (BLC) and the linguistics department’s Survey of California and Other Indian Languages research center, which curates the BLC’s linguistic field recordings.
The new site resolves nagging problems with incompatible catalogs and different content formats that have complicated attempts at coordinated use of the BLC’s nearly 2,000 hours of audio recordings and 8,000 audio clips in about 90 languages dating back to1949, and the Survey’s 60,000 scanned images of manuscripts, notes and lexical “file slips” that can be used to compile a dictionary.
The most important content from the Survey has been digitized, Garrett said, but it will still take a few more years to properly scan and catalog all of the archive’s more than 150 linear feet of written documentation contained in 186 individual collections.
By summer’s end, the CLA will expand further when it adds a detailed catalog of approximately 2,700 wax cylinder recordings – mostly of California Indian tribal songs – dating back to 1901 and safeguarded at the campus’s Phoebe Hearst Museum of Anthropology.
“Everyone who’s interested in those languages will be astonished to learn how much is available there,” said Garrett.
Later, archive leaders hope to add a catalog of Bancroft Library journals, diaries and other documents relating to indigenous languages of California and the West – like the original 1922 field notes on the now-extinct language of Wiyot, as recorded by the pioneering cultural and linguistic anthropologist Gladys Reichard.
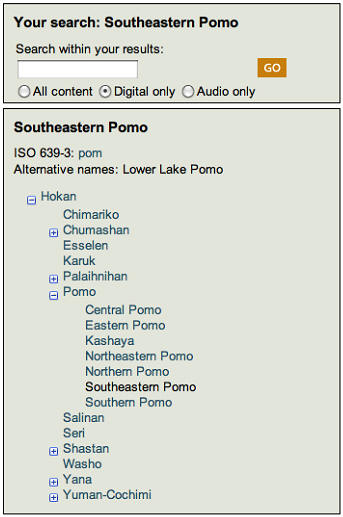
Meanwhile, CLA visitors who register can now listen to an account of the origins of the Pomo languages; read linguist and ethnographer J.P. Harrington’s handwritten notes on Chochenyo, the indigenous language of the East Bay; or peruse information collected during a 1957 survey of a few speakers of the Central California coastal region’s Ohlone languages and records of words and pronunciation guides in the now extinct language.
A map interface enables archive visitors to zoom around California looking for materials, and the site provides the precise geographical place where a recording was made. More work is being done to align the archive’s written materials to a location, which can be tricky, as a researcher’s records may reflect numerous sites.
An especially alluring feature for linguists is a genealogical tree that the CLA provides for each language of California and North America.
The CLA project was developed with funding from the National Endowment for the Humanities. In addition to Garrett and Mark Kaiser, director of the BLC, the CLA has been constructed by UC Berkeley’s linguistics department information technology specialist Ronald Sprouse and graduate students Amy Campbell, Hannah Haynie, Justin Spence, John Sylak and former student Maziar Toosarvandani, who received his Ph.D. in 2010.