
Research Bio
Jack Gallant is a cognitive neuroscientist whose research investigates how the brain represents and processes naturalistic information. He is best known for developing computational models that decode brain activity to reveal how sensory and cognitive information is encoded in the cerbral cortex. Gallant’s research integrates neuroimaging, computational neuroscience, and machine learning to map brain function during perception, language processing, and cognition. His work has advanced understanding of the neural basis of cognition and inspired new methods in brain-computer interfaces and AI.
He is Chancellor’s Professor of Psychology and Neuroscience at UC Berkeley, and co-director of the Henry H. Wheeler Brain Imaging Center. His research has been published in Nature, Science, and Neuron, and it is featured routinely in popular newspapers and magazines. At Berkeley, he teaches systems neuroscience and computational modeling, mentoring graduate students in the areas of neuroimaging, computational modeling of the brain, brain decoding and cognitive neuroscience.
Research Expertise and Interest
computational neuroscience, vision science, attention, fMRI, language, natural scene perception, brain encoding, brain decoding
In the News

Eleven UC Berkeley Faculty Members Elected Fellows

New Study Shows How the Brain Reacts Emotionally to the Real World
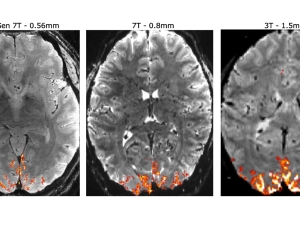
Innovative Design Achieves Tenfold Better Resolution for Functional MRI Brain Imaging
Berkeley Talks: Mapping the Brain to Understand Health, Aging and Disease

Lost your keys? Your cat? The brain can rapidly mobilize a search party
Scientists at the University of California, Berkeley, have discovered that when we embark on a targeted search, various visual and non-visual regions of the brain mobilize to track down a person, animal or thing.
New video shows reconstruction of 'brain movies'
UC Berkeley scientists Jack Gallant and Shinji Nishimoto have wowed the world by using brain scans and computer modeling to reconstruct images of what we see when we’re watching movies. UC Berkeley broadcast manager Roxanne Makasdjian has produced a video of how they achieved this breakthrough, and where they’re headed.

Scientists use brain imaging to reveal the movies in our mind
Imagine tapping into the mind of a coma patient, or watching one’s own dream on YouTube. With a cutting-edge blend of brain imaging and computer simulation, UC Berkeley scientists are bringing these futuristic scenarios within reach. Using functional Magnetic Resonance Imaging (fMRI) and computational models, researchers have succeeded in decoding and reconstructing people’s dynamic visual experiences – in this case, watching Hollywood movie trailers.
Teaching
Seminars [NEU 290 - 002]
Neuroscience Graduate Research [NEU 292 - 014]
Neuroscience Research Review [NEU 295 - 010]
Research in Vision Science [VISSCI 299 - 006]
Cognitive Neuroscience [NEU 128 - 001]
Functional MRI Methods [NEU 271 - 001]
Neuroscience Graduate Research [NEU 292 - 014]
Neuroscience Research Review [NEU 295 - 010]
Research in Vision Science [VISSCI 299 - 012]
Neuroscience Graduate Research [NEU 292 - 014]
Neuroscience Research Review [NEU 295 - 010]
Research in Vision Science [VISSCI 299 - 006]